Automatically detecting security-relevant system weaknesses¶
by Felix Wolff | winter term 2017/2018
Code Repository Mining seminar at Hasso-Plattner-Institute
This document serves as the starting point into the documentation of the accomplishments of this semester. It explains the reasoning behind the technical solution implemented for the topic Effects of high-profile incidents on code. It first covers the application and its features. The following contents are about the data analysis and the logic leading to several implementation decisions. The data structure and the incurred computing load inside the database is outlined then. The topical shift away from the original topic is explained at the close of this chapter.
The result of this project is a client-server application which scans the locally installed programs and libararies for known vulnerabilities registered at NIST. For the found vulnerabilities, promising references and experts on Twitter/GitHub are recommended.
The code for this project can be found here. The intermediate presentation slides can be found here. The final presentation slides (going into technical detail and code) can be found here. The graphs are created using plotly and encourage interactive exploration! Most keywords are not explained in this text but linked to other sources. The queries used to create the graphs may be revealed by clicking a button, such as the one below.
import requests
import time
import re
import psycopg2
import os
import plotly.plotly as py
import plotly.graph_objs as go
import cufflinks as cf
import pandas as pd
from scipy import stats
PLOTLY_UN = os.environ.get("PLOTLY_UN")
PLOTLY_TOKEN = os.environ.get("PLOTLY_TOKEN")
POSTGRES_DB_NAME = os.environ.get("POSTGRES_DB_NAME")
POSTGRES_DB_UN = os.environ.get("POSTGRES_DB_UN")
POSTGRES_DB_PW = os.environ.get("POSTGRES_DB_PW")
POSTGRES_DB_HOST = os.environ.get("POSTGRES_DB_HOST")
connect_to_db = 'postgresql+psycopg2://' + \
POSTGRES_DB_UN + ':' + POSTGRES_DB_PW + '@' + \
POSTGRES_DB_HOST + '/' + POSTGRES_DB_NAME;
%load_ext sql
%config echo=False
%sql $connect_to_db
connection = psycopg2.connect(dbname=POSTGRES_DB_NAME, user=POSTGRES_DB_UN, password=POSTGRES_DB_PW);
cursor = connection.cursor()
A motivational introduction¶
When the Heartbleed bug was published on April 1st, 2014, many SSL-secured websites were suddenly open to attack. A fix was published on April 7th.
On April 8th, data was stolen from the Canada Revenue Agency by exploiting Heartbleed. An unfortunate incident that would have been avoidable.
Had the systems administrators known about this vulnerability, this might not have happened. The following section shall introduce a tool that would have come in handy in this situation - a tool for detecting system vulnerabilities and give helpful pointers.
The technical solution¶
A prototypical implementation of this tool is the script client/checksystem.py. Upon execution, all packages installed via the distribution-default package manager are checked for known weaknesses. Grouped by package it puts out a block of information for every weakness that is found. This might look like the following:
CVE-2013-0166 released on Friday 08. February 2013
OpenSSL before 0.9.8y, 1.0.0 before 1.0.0k, and 1.0.1 before 1.0.1d does not properly perform signature verification for OCSP responses, which allows remote OCSP servers to cause a denial of service (NULL pointer dereference and application crash) via an invalid key.
Official NIST entry: https://nvd.nist.gov/vuln/detail/CVE-2013-0166
Recommended information source (16.4% of total references for this CWE): http://www.kb.cert.org/vuls/id/737740
A knowledgeable Twitter and Github user might be: https://github.com/delphij - as 91.5% of his posts are on this kind of CWELine by line this block reveals the following information:
- The CVE-ID and its publishing date
- A brief description of the vulnerability, also taken from the National Institute for Standards and Technology (NIST)
- The official NIST database link
- An information source which might be helpful to the user
- A person who is both active on Github and Twitter in the domain of cybersecurity and who might be of assistance in the domain of the CVEs type, the CWE. He or she might be willing to offer consulting services.
This application offers a huge improvement over the complicated search form at NIST. Furthermore it contributes to the trend of automatic vulnerability detection systems, as made evident by JFrogs XRay and GitHubs recent addition to its data services. As described in the repository, the client has a demo mode for faster execution.
Data origins¶
Three datasets from different sources were cobined to create the foundations for the application and analysis presented in this document - all inside a PostgreSQL database:
- A complete ghtorrent dump
- Tweets referring to CVE-IDs that were also referred to by commits from the above source. To accomplish this, TweetScraper was forked and extended with a PostgreSQL backend option.
- An extraction of relevant data via ETL from the cve-search project.
The relevant tables and their origin are denoted below (views in italic):
| ghtorrent | cve-search | |
|---|---|---|
| commits | cve_referring_tweets | cwe |
| view_commits_search_for_cve | view_cve_referring_tweets_extracted_domains | cve_per_product_version |
| view_cve_referring_tweets_extracted_cves | cve_cwe_classification | |
| cvereference | ||
| view_cvereference_extracted_domains | ||
| cve |
On the client side, the package information is extracted from the Linux distribution-default package manager. Attention was paid to make this process easily expandable to other operating systems. A brief addition to this file can expand the number of supported systems..
User recommendations¶
In order to recommend a person from the plethora of Twitter and GitHub users who might be an expert on a family of software errors, several criteria were introduced:
- The user uses the same name in both GitHub and Twitter.
- The user has tweeted about the same CWE as the current CVE in question. (I.e. he knows this type of vulnerability)
The following paragraphs explain the analysis and reasoning behind these criteria. An important assumption here is that identical usernames belong to the same person. Testing a small sample, this held true for the following users:
- zisk0 - Twitter - GitHub
- nahi - Twitter - GitHub
- fdiskyou - Twitter - GitHub
- citypw - Twitter - GitHub
- breenmachine - Twitter - GitHub
As the following graph shows, more GitHub users are becoming more active on Twitter and their tweets are fairly evenly distributed across the users every year. This trend needs to be seen in connection with the growing number of GitHub users.
query = """
SELECT
DISTINCT t.username,
extract(year from t.timestamp) AS t_year,
COUNT(t.id) OVER (PARTITION BY t.username, extract(year from t.timestamp)) AS t_user_count,
COUNT(t.id) OVER (PARTITION BY extract(year from t.timestamp)) AS t_year_count
FROM cve_referring_tweets t
JOIN view_commit_data_search_for_cve vc ON vc.name = t.username
ORDER BY t.username, t_year"""
df = pd.read_sql_query(query, connection)
lyt = go.Layout(
title='Same Github & Twitter handles over time and share-of-year-volume',
font=dict(family='Open Sans, monospace', size=12, color='#888888'),
autosize=False,
height=800,
margin=go.Margin(
l=175
),
xaxis=dict(title='CWE IDs'),
yaxis=dict(title='Usernames')
)
data = [
{
'x': df.t_year,
'y': df.username,
'mode': 'markers',
'marker': {
'color': df.t_user_count / df.t_year_count,
'size': 10,
'showscale': True,
"colorscale": [ [0,"rgb(40,171,226)"], [1,"rgb(247,146,58)"] ]
}
}
]
fig = go.Figure(data = data, layout = lyt)
py.iplot(fig, filename='same-userhandles-time-volume-bubble-chart')
Not only is the number of Tweets increasing every year, but also do some users appear to be knowledgeable in certain areas. This becomes apparent when plotting their share of the total number of tweets for a given CWE against the individual CWE IDs and usernames. The graph below shows a selection of users who have contributed more than 10% to the total number of tweets:
query = """
SELECT
DISTINCT t.username,
ccc.cweid,
COUNT(t.id) OVER (PARTITION BY t.username, ccc.cweid) AS t_cwe_count,
COUNT(t.id) OVER (PARTITION BY ccc.cweid) AS t_count
FROM cve_referring_tweets t
JOIN view_commit_data_search_for_cve vc ON vc.name = t.username
JOIN view_cve_referring_tweets_extracted_cves ec ON t.id = ec.tweet_id
JOIN cve_cwe_classification ccc ON ec.cve = ccc.cveid"""
df = pd.read_sql_query(query, connection)
lyt = go.Layout(
title='Same Github & Twitter handles over time and greater-than-10%-share-of-cwe-volume',
font=dict(family='Open Sans, monospace', size=12, color='#888888'),
autosize=False,
height=600,
margin=go.Margin(
l=175
),
xaxis=dict(title='CWE IDs'),
yaxis=dict(title='Usernames')
)
ratio = df.t_cwe_count / df.t_count * 100
data = [
{
'x': df.cweid[ratio > 0.1],
'y': df.username[ratio > 0.1],
'mode': 'markers',
'marker': {
'color': ratio,
'size': 10,
'showscale': True,
"colorscale": [ [0,"rgb(40,171,226)"], [1,"rgb(247,146,58)"] ],
"colorbar": {"ticksuffix":"%"}
}
}
]
fig = go.Figure(data = data, layout = lyt)
py.iplot(fig, filename='same-userhandles-cwe-volume-bubble-chart')
Reference recommendation¶
Recommended information source (16.4% of total references for this CWE): http://www.kb.cert.org/vuls/id/737740Shown above is a reference recommendation, and this section shall give insight into the logical choices behind it. Initially, high hopes were put on the community-curated references from Twitter. The following section will also explain why official NIST references were recommended instead.
Twitter references¶
All tweets referring to CVE-IDs from the ghtorrent database were crawled with a forked version of TweetScraper. From these tweets, a regular expression extracted every URL - an assumption that URLs posted with a CVE-ID represented a connection. Such a tweet with an embedded URL might look like the following:
another talk about CVE-2015-1805 https://t.co/4JcyIC14SV
— Electric Wizard (@memcorrupt) October 12, 2016
After extracting and connecting CVE-IDs to URLs, the domains were extracted from URLs in a second step. This was done to determine the popularity of a reference domain via aggregation. Unfortunately, the fact that most Twitter bots and Twitter itself use link shorteners, was missed. The aggregation was executed relatively late in the project, so there was not enough time left to perform a full URL resolution on 20000+ addresses.
Even though no individual reference domains can be distinguished, the following bubble chart clearly shows an increasing number of tweets about vulnerabilities every year.
query = """
SELECT *
FROM (
SELECT ted.domain,
extract(year from t.timestamp) AS t_year,
SUM(t.retweet_count) AS rt_cnt,
SUM(t.favorite_count) AS fav_cnt,
COUNT(ted.domain) AS cnt
FROM view_cve_referring_tweets_extracted_domains ted
JOIN cve_referring_tweets t
ON t.id = ted.tweet_id
GROUP BY ted.domain, t_year
ORDER BY t_year DESC, cnt DESC
) a
WHERE cnt > 500"""
df = pd.read_sql_query(query, connection)
df = df.sort_values(by=['domain'], ascending = False)
lyt = go.Layout(
title='Twitter 500+ reference sources by year and frequency',
autosize=False,
height=500,
margin=go.Margin(
l=175
),
xaxis=dict(title="Year"),
yaxis=dict(title="Reference domain")
)
data = [
{
'x': df.t_year,
'y': df.domain,
'mode': 'markers',
'marker': {
'color': df.cnt,
'size': 10,
'showscale': True,
"colorscale": [ [0,"rgb(40,171,226)"], [1,"rgb(247,146,58)"] ]
}
}
]
fig = go.Figure(data = data, layout = lyt)
py.iplot(fig, filename='twitter-source-cwe-popularity-bubble-chart')
NIST references¶
Having determined that tweeted references were unfit for use until processed further, the official NIST references attached to each CVE were analyzed and found to be good for recommendation. Since CVE-IDs are given away in blocks, their registration timestamp may be earlier than the initial disclosure of the vulnerability. Because of this, a time-wise analysis would have been unclean.
Looking at a topical distribution segmented by CWE-IDs instead, it becomes apparent that references usually come from certain sources in the case of a selected vulnerability type. The following figure depicts which ones provide more than a 25% share of the total number of references to a specific CWE-ID.
query = """
SELECT *, nrefs/nrefstotal::float * 100 AS refshare
FROM (
SELECT DISTINCT cr.domain,
cvecwe.cweid,
COUNT(cr.domain) OVER (PARTITION BY cvecwe.cweid) AS nrefstotal,
COUNT(cr.domain) OVER (PARTITION BY cr.domain, cvecwe.cweid) AS nrefs
FROM view_cvereference_extracted_domains cr
JOIN cve_cwe_classification cvecwe
ON cr.cveid = cvecwe.cveid
ORDER BY nrefs DESC
) a
WHERE nrefs/nrefstotal::float > 0.25"""
df = pd.read_sql_query(query, connection)
df = df.sort_values(by=['domain'], ascending = False)
lyt = go.Layout(
title='NIST reference sources by CWE and 25%+-share of total CWE references',
autosize=False,
height=600,
margin=go.Margin(
l=175
),
xaxis=dict(title="CWE-ID"),
yaxis=dict(title="Reference domain")
)
data = [
{
'x': df.cweid,
'y': df.domain,
'mode': 'markers',
'marker': {
'color': df.refshare,
'size': 10,
'showscale': True,
"colorscale": [ [0,"rgb(40,171,226)"], [1,"rgb(247,146,58)"] ],
"colorbar": {"ticksuffix":"%"}
}
}
]
fig = go.Figure(data = data, layout = lyt)
py.iplot(fig, filename='nist-reference-cwe-popularity-bubble-chart')
Data structure and size¶
The following diagrams depict how the views that are ultimately used in the application are composed out of different tables. The super-second response time of the application can be explained when looking at the cardinalities of each table and view. All of the views encapsule long-running queries (5min to 2hours with the current cardinalities). Nonetheless, there exists potential for optimization via indices and view expansion with attributes.
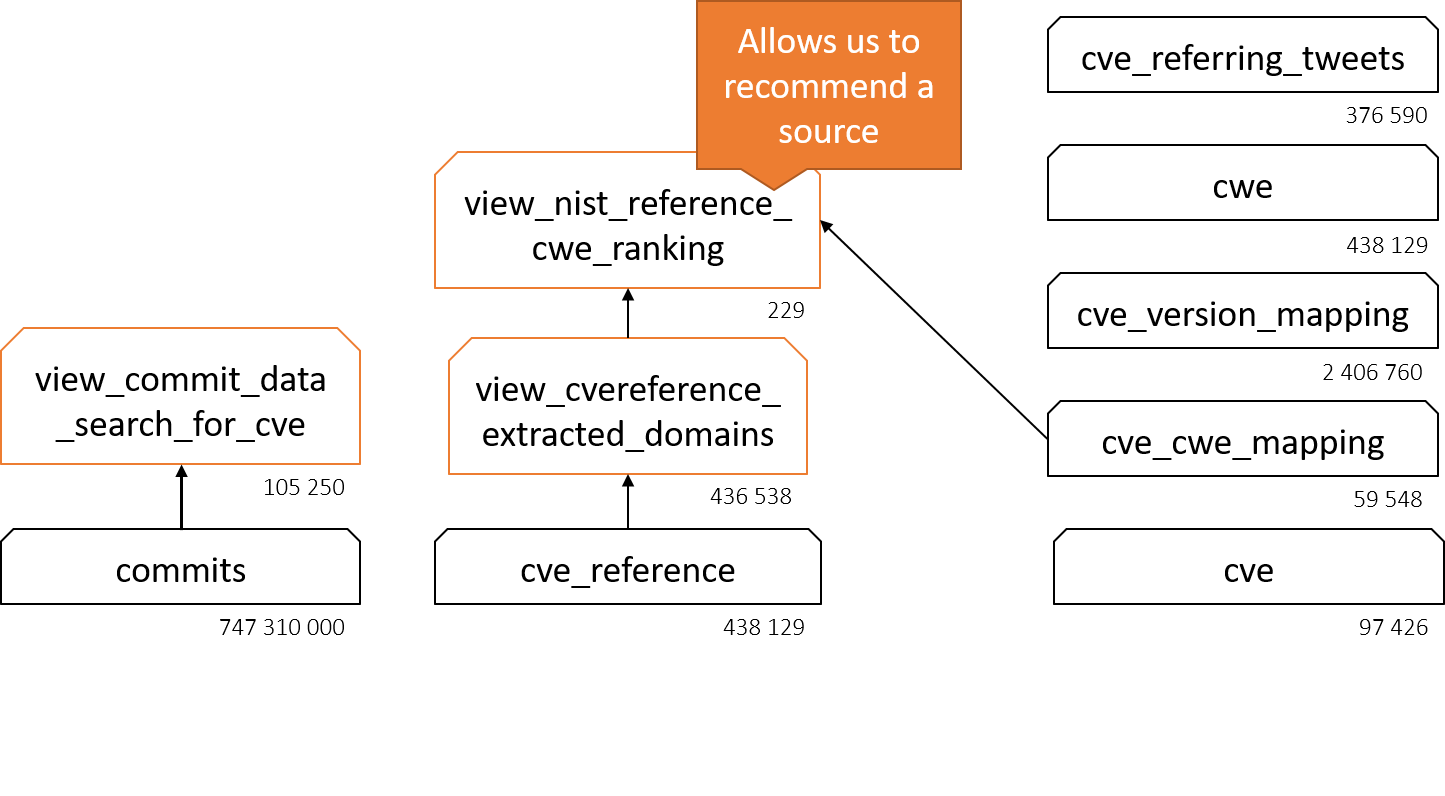
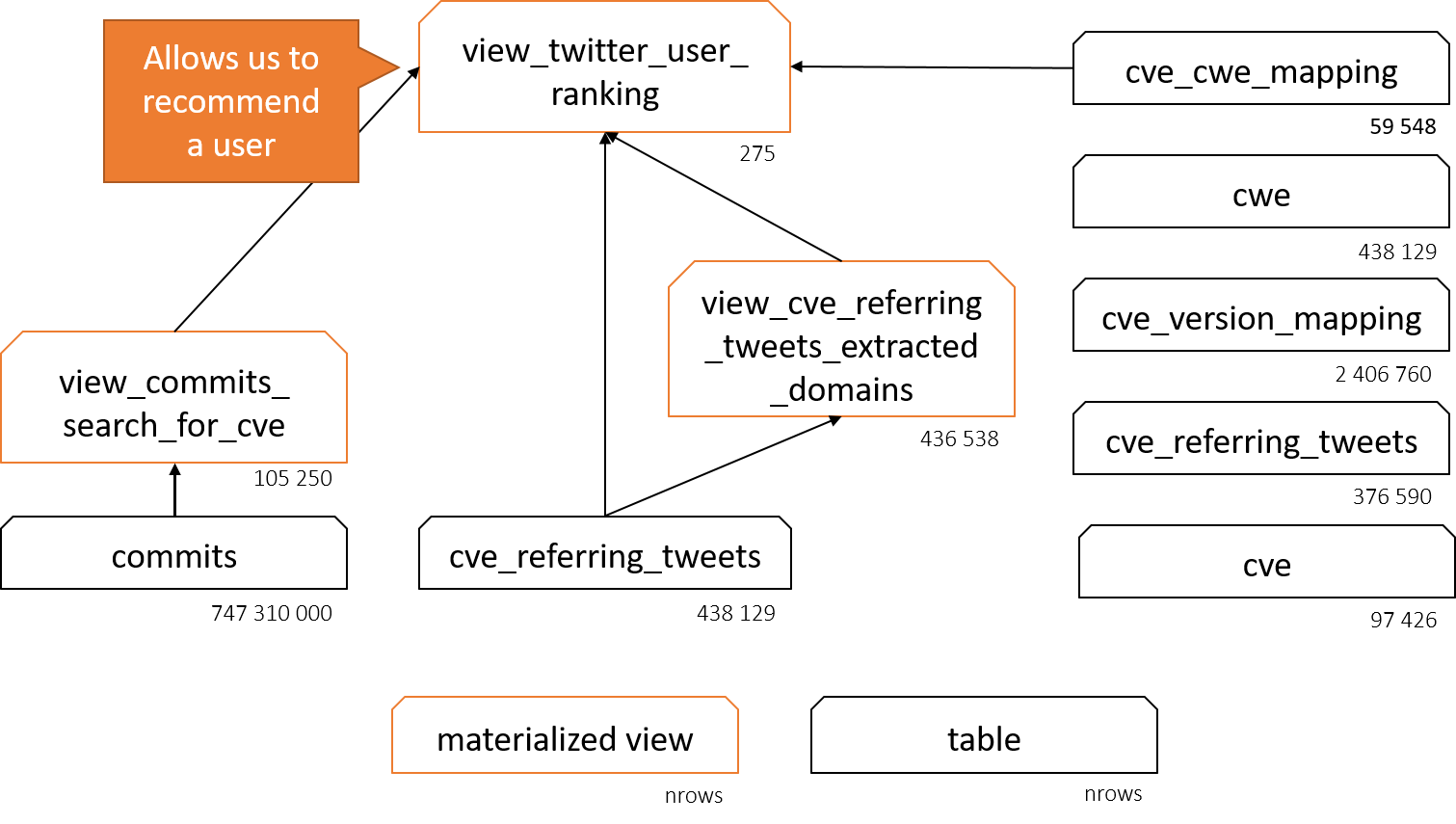
Future work¶
Some parts of the application still need work, especially run-time optimization. These work items are sorted from being considered easiest to hardest:
- Introduce indices to speed up certain lookups and joins a. Keep an index on CVE-IDs that also have a CWE-ID
- Rewrite views to speed up and reduce the number of joins
- Unshorten the Twitter references, e.g. via Python and urlunshort
- Implement easy updating of both cve-search and Twitter information without intermediary saving with cve-search
- Implement version matching inside a SQL (for details see here)
- Implement a reliable product matching heuristic (for details see here)
- Implement the system as a notification service. Right now, the application scans the users system completely every time it is invoked. There is merit to the idea of saving the system configuration on the server side, and reacting to vulnerabilities as they are released. Centralized saving of information that can reveal security vulnerabilities is unwise, which could be mitigated via running stubs of the database on each client. An alternative and easier approach might be a client that continously polls for vulnerability updates.
Apart from the application, the collected data offers further potential for answering further questions:
- What vulnerabilities are common for what type of application? What would be a good thing to know about when trying to develop such a piece of software?
- What vulnerabilities are common for which programming language? This might be used as input by application developers.
- Which people on GitHub or Twitter usually react the fastest after the disclosure of a vulnerability? These first-movers advantages could be used in the user recommendation ranking.
Discussion¶
We established that the growing awareness about security issues is also visible in the increase of CVE-related commits and tweets. Furthermore, we found out that a growing number of GitHub users is active on Twitter as well and vice versa. These users could be considered knowledgeable in some fields, making them candidates for security consultants.
We presented an application which can help uncover overlooked security flaws in a system. It recommends information sources and knowledgeable users, allowing the system administrators to become informed and take action.
The value add comes from the data processed by the application, making its procurement pipelines the most important part of it. This has been highlighted in the previous section. While important data privacy and security issues have not been adressed in this work, this work contributes to the trend of automatic security flaw detection systems. It shows another possibility on how such a system might work, in a way it has not yet been done in the open source world.
Justification of topic adaption¶
The initial research question was titled Effects of High-profile Incidents on Code and described as follows:
- Incidents with widespread media coverage (e.g. Apple "goto fail" bug, Heartbleed, Loss of Space Missions, …) often result from mistakes that could have been avoided by strictly following best practices.
- Goal: Find out if such incidents have large-scale effects on code quality (e.g. "goto fail" causing increased use of curly braces in single-line if-blocks across GitHub)
Continuing the example, the goto-fail bug is identified as CVE-2014-1266 and this bug is being referenced two times in the entire ghtorrent commit history. The initial assumption was that programmers learn from these bugs and change their programming style to be more defensive. Ironically, one of the two commit messages (the other one is a gcc merge commit) read this instead:
Makefile.in: add -Wunreachable-code
I was reading about the CVE-2014-1266 SSL/TLS Apple bug on
ImperialViolet and learnt that clang has a separate flag for
unreachable code, -Wunreachable-code, that is not included
in the -Wall warnings [1].
So, let's add -Wunreachable-code to Makefile.in.
[1] https://www.imperialviolet.org/2014/02/22/applebug.htmlAlso, most of the bugs that receive a lot of media attention are a mix of bad design and human error. Practically no other bug can be attributed to a simple programming error as in the case of goto-fail. Without context it is hard to find out whether such behavior was not intended.
This lead us to move away from looking at high-profile code incidents and focus on registered ones. CVE-IDs are being referenced more and more across GitHub, showing the growing awareness for security vulnerabilities - evidenced by the graph below.
import plotly.plotly as ply
import plotly.graph_objs as go
import pandas as pd
import datetime as dt
query = """
SELECT a.date, a.shacount/b.shacount::float AS shacount
FROM (
SELECT DATE(timestamp) as date, COUNT(sha) AS shacount
FROM view_commit_data_search_for_cve
GROUP BY date
ORDER BY date
) a
INNER JOIN
view_commit_data_commits_per_day b
ON a.date = b.date
"""
df = pd.read_sql_query(query, connection)
ply.iplot({
'data': [
go.Scatter(x=df.date, y=df.shacount,
line=dict(color = ('rgb(40,171,226)')))
],
'layout': {
'title': "Adjusted reactions to CVE entries over time",
'xaxis': { 'range': ['2012-01-01','2017-12-31'], 'title': 'Year'},
'yaxis': { 'range': [0, 0.003], 'title': 'Percentage of total commits on a given day', 'tickformat': '.2%'}
}}, filename="cve-reactions-adjusted-over-time")